Newcomers to the field of Artificial Intelligence (AI) often see the term ‘language model’ tossed around when discussing Natural Language Processing (NLP) tasks without any proper clarification of its importance and usage in solving real-world problems.
So, this tutorial blogpost aims at demystifying language models by defining what a language model is, describing the common types of language models and providing a concrete example of using a popular language model to solve a common Machine Learning (ML) classification problem.
What is a language model?
When talking about textual data, a language model is a mathematical model that assigns a probability to a sequence of words. The most common type of language model is the Bag of Words model (BoW). Bag of words is a representation of text where each word is represented by a number. This can be done by assigning a unique number to each word, or by using a technique called “hashing.”. For instance, the number of times a certain word appears in a document is called term frequency, which is part of the BoW language model [1].
Types of language models
Language models can be either rule-based, statistical, or based on neural networks:
- Rule-based language models are based on a set of rules; these models are less common than the other types of models. They are based on a set of rules that define how words can be combined. These rules can be hand-crafted or learned from data. Rule-based language models are less accurate but can be used with less data.
- Statistical language models are based on statistical methods and data; such models are more common than rule-based language models. They are trained on large amounts of data and can be used to calculate the probability of any word sequence, such as the BoW model that we discussed earlier. Statistical language models are more accurate compared to rule-based models but require more data to train.
- Neural network language models use continuous representations or embeddings of words to make predictions making use of neural networks. These are new players in the NLP town and have surpassed the statistical language models in their effectiveness. They use different kinds of Neural Networks to model language and just like statistical models, they require more data to train them [2].
What is the purpose of language models?
Language models are used in NLP and ML tasks such as speech recognition, question answering, document or text classification, and machine translation.
To illustrate a real-world example of using language models, let’s look at Gmail’s spam filtering text classification problem.
The spam filtering problem is the problem of designing a system that can automatically detect spam emails and flag them for the user, as in the figure below. This is a difficult problem because spam emails are often very similar to regular emails, and it can be hard to design a system that can accurately distinguish between them. There are many different approaches to this problem, but one common approach is to use a supervised machine learning algorithm with a language model to learn from a dataset of labeled emails (i.e., emails that have been manually labeled as spam or not spam). The algorithm can then be used to classify new emails as spam or not spam [3].

Machine learning researchers are constantly looking for ways to improve the performance of language models. One area of research is to develop new algorithms that can better learn from data, as we explained in the spam filtering problem. Another area of research is to develop new ways to represent data that can be more easily learned by language models.
BERT as a neural network language model
A popular type of neural network-based language models is BERT, which was
created in 2017 by Google and fine-tuned on the Wikipedia corpus that contains 2.5 billion words. BERT is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context, just like how humans try to use surrounding terms in sentences to identify the meaning of unknown words.
As a language model, BERT was pre-trained using text from Wikipedia and can be fine-tuned with datasets to solve any type of classification problems like question answering.
However, as a neural network, Bidirectional Encoder Representations from Transformers (BERT) is a machine learning framework for NLP that uses deep learning algorithms to better understand the meaning of ambiguous language [4]. BERT is a type of transformer neural network that is pre-trained on text from Wikipedia and can be fine-tuned with any type of dataset to suit user’s needs, such as performing sentiment analysis, or question answering, as seen in the figure below.
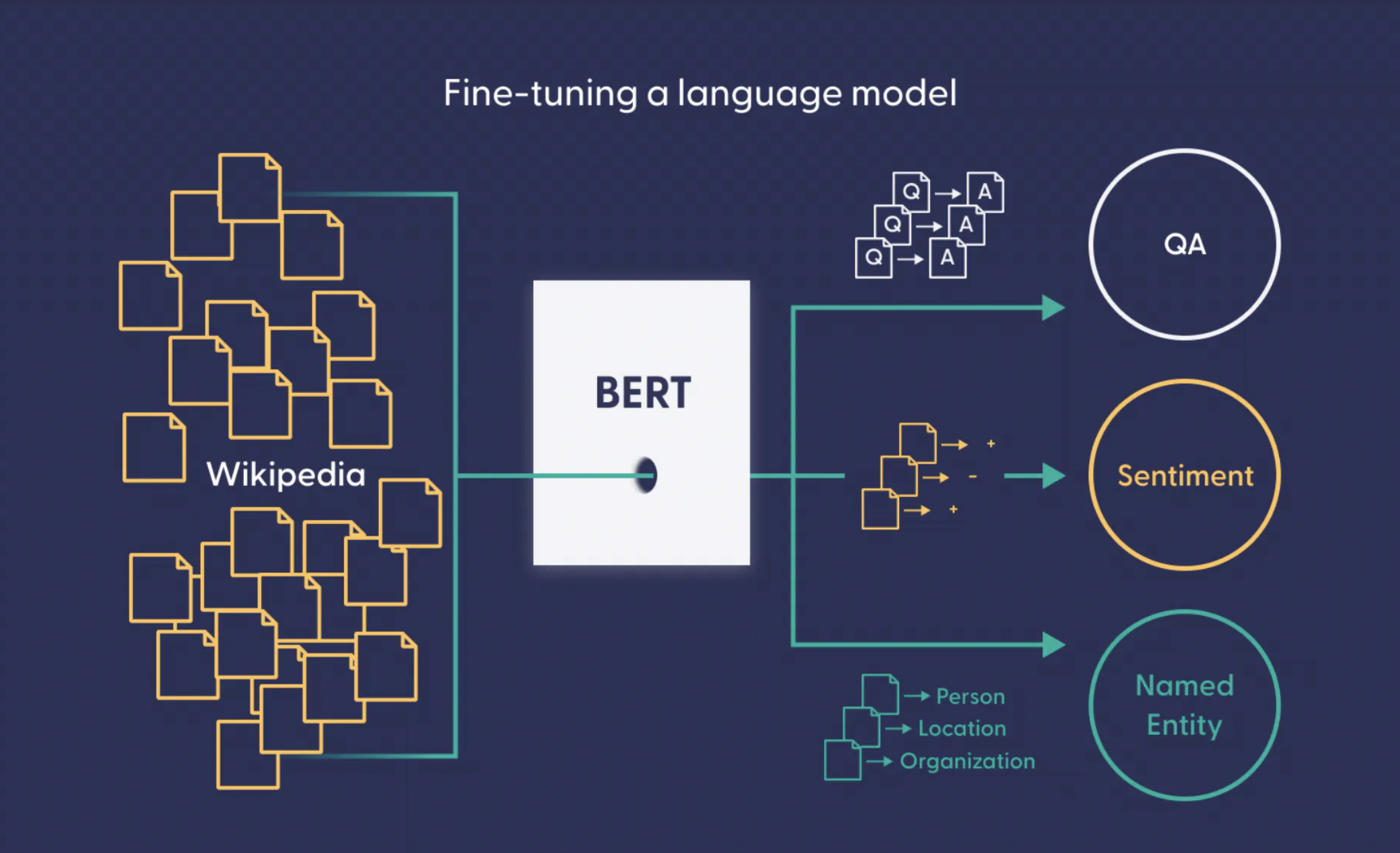
Now that we briefly described BERT, we will illustrate its usage on the problem of detecting toxicity from comments on Reddit. The dataset that we will use was part of a study that investigates the toxic behavior of users on Reddit [5]. The dataset (can be found here) consists of comments from the subreddit r/AskReddit, where each comment can be either non-toxic, slightly-toxic, or highly-toxic. So, the dataset is a great candidate for testing our understanding of language models by using and fine-tuning a BERT neural network language model.
First, we will install a light-weight library called ktrain to help with simplifying the training of neural network models like BERT, then we will import the required libraries as follows:
!pip install -q ktrain # -q is a quiet option for less noise in the console output import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) seed_value=13 import re import os import math from sklearn.utils.class_weight import compute_class_weight from sklearn.preprocessing import MultiLabelBinarizer import tensorflow as tf from tensorflow.keras import activations from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, roc_auc_score from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix import ktrain from ktrain import text
Then, clean the dataset using any appropriate method and partition the dataset into training, testing, and validation splits. Here, we cleaned the dataset based on special characteristics typically found in data retrieved from Reddit. Furthermore, we computed the class weight to supply it to the neural network model at the training phase. The toxicity detection dataset is severely imbalanced, with 81.57% non-toxic, 11.81% slightly-toxic, and 6.62% highly-toxic comments. Therefore, using the class weights for training is a good idea to ensure that the model pays more attention to minority classes.
#Define class names classes = ["highly_toxic","slightly_toxic","non_toxic"] #Function to partition data equally across classes def get_dataset_partitions_pd(df, train_split=0.8, val_split=0.1, test_split=0.1, target_variable=None): assert (train_split + test_split + val_split) == 1 # Only allows for equal validation and test splits assert val_split == test_split # Shuffle df_sample = df.sample(frac=1, random_state=seed_value) # Specify seed to always have the same split distribution between runs # If target variable is provided, generate stratified sets if target_variable is not None: grouped_df = df_sample.groupby(target_variable) arr_list = [np.split(g, [int(train_split * len(g)), int((1 - val_split) * len(g))]) for i, g in grouped_df] train_ds = pd.concat([t[0] for t in arr_list]) val_ds = pd.concat([t[1] for t in arr_list]) test_ds = pd.concat([v[2] for v in arr_list]) else: indices_or_sections = [int(train_split * len(df)), int((1 - val_split) * len(df))] train_ds, val_ds, test_ds = np.split(df_sample, indices_or_sections) return train_ds, val_ds, test_ds #Function to get class weights based on distribution of data in rows def generate_class_weights(class_series, multi_class=True, one_hot_encoded=False): if multi_class: # If class is one hot encoded, transform to categorical labels to use compute_class_weight if one_hot_encoded: class_series = np.argmax(class_series, axis=1) # Compute class weights with sklearn method class_labels = np.unique(class_series) class_weights = compute_class_weight(class_weight='balanced', classes=class_labels, y=class_series) return dict(zip(class_labels, class_weights)) else: # It is neccessary that the multi-label values are one-hot encoded mlb = None if not one_hot_encoded: mlb = MultiLabelBinarizer() class_series = mlb.fit_transform(class_series) n_samples = len(class_series) n_classes = len(class_series[0]) # Count each class frequency class_count = [0] * n_classes for classes in class_series: for index in range(n_classes): if classes[index] != 0: class_count[index] += 1 # Compute class weights using balanced method class_weights = [n_samples / (n_classes * freq) if freq > 0 else 1 for freq in class_count] class_labels = range(len(class_weights)) if mlb is None else mlb.classes_ return dict(zip(class_labels, class_weights)) #Function to clean Reddit data def clean(text, newline=True, quote=True, bullet_point=True, link=True, strikethrough=True, spoiler=True, code=True, superscript=True, table=True, heading=True): """ Cleans text (string). Removes common Reddit special characters/symbols: * \n (newlines) * > (> quotes) * * or &#x200B; (bullet points) * []() (links) * etc (see below) Specific removals can be turned off, but everything is on by default. Standard punctuation etc is deliberately not removed, can be done in a second round manually, or may be preserved in any case. """ # Newlines (replaced with space to preserve cases like word1\nword2) if newline: text = re.sub(r'\n+', ' ', text) # Remove resulting ' ' text = text.strip() text = re.sub(r'\s\s+', ' ', text) # > Quotes if quote: text = re.sub(r'\"?\\?&?gt;?', '', text) # Bullet points/asterisk (bold/italic) if bullet_point: text = re.sub(r'\*', '', text) text = re.sub('&#x200B;', '', text) # []() Link (Also removes the hyperlink) if link: text = re.sub(r'\[.*?\]\(.*?\)', '', text) # Strikethrough if strikethrough: text = re.sub('~', '', text) # Spoiler, which is used with < less-than (Preserves the text) if spoiler: text = re.sub('<', '', text) text = re.sub(r'!(.*?)!', r'\1', text) # Code, inline and block if code: text = re.sub('`', '', text) # Superscript (Preserves the text) if superscript: text = re.sub(r'\^\((.*?)\)', r'\1', text) # Table if table: text = re.sub(r'\|', ' ', text) text = re.sub(':-', '', text) # Heading if heading: text = re.sub('#', '', text) return text def get_data(): dataset = pd.read_csv('trainingDataset-toxicComments.csv') dataset = dataset.sample(frac=1,random_state=seed_value) dataset['comment_text'] = dataset['comment_text'].apply(lambda x: clean(x)) myLabels = dataset[classes] dataset['category'] = myLabels.idxmax(axis=1) dataset['label']= dataset['category'].map({'highly_toxic':0, 'slightly_toxic':1,'non_toxic':2}) y = dataset[['label']] htoxic, stoxic, neither = np.bincount(dataset['label']) total = neither + stoxic + htoxic print('Examples:\n Total: {}\n highly toxic: {} ({:.2f}% of total)\n'.format( total, htoxic, 100 * htoxic / total)) print('Examples:\n Total: {}\n slightly toxic: {} ({:.2f}% of total)\n'.format( total, stoxic, 100 * stoxic / total)) print('Examples:\n Total: {}\n Neither: {} ({:.2f}% of total)\n'.format( total, neither, 100 * neither / total)) print() weights = generate_class_weights(myLabels.values, multi_class=True, one_hot_encoded=True) print("Class weights:") print(weights) train_ds, val_ds, test_ds = get_dataset_partitions_pd(dataset, target_variable="label") print(f'Distribution in training set: \n{train_ds["label"].value_counts().sort_index() / len(train_ds)}\n\n'+ f'Distribution in validation set: \n{val_ds["label"].value_counts().sort_index() / len(val_ds)}\n\n'+ f'Distribution in testing set: \n{test_ds["label"].value_counts().sort_index() / len(test_ds)}') train_sentences = train_ds['comment_text'].fillna("fillna").str.lower() y_train = train_ds['label'].values.astype(np.int32) val_sentences = val_ds['comment_text'].fillna("fillna").str.lower() y_val = val_ds['label'].values.astype(np.int32) test_sentences = test_ds['comment_text'].fillna("fillna").str.lower() y_tests = test_ds['label'].values.astype(np.int32) return train_sentences, y_train, val_sentences, y_val, test_sentences, y_tests,weights
Calling the above function to process the dataset, clean it and partition it can be done as follows:
print('Result of processing the whole train set:') train_sentences, y_train, val_sentences, y_val, test_sentences, y_tests,weights = get_data()
The following step involves defining the exact BERT pre-trained language model name that will be fine-tuned as a transformer model to detect toxic comments. In this tutorial, we used the basic uncased BERT model, but there are other models that can be used like BERT tiny, large, medium in cased and uncased variations. For more information, please refer to Google research’s explanation of the various flavors of BERT, which can be found here.
MODEL_NAME = 'bert-base-uncased' categories = ['Advertising','Customer experience','News','Responding to customers','Socially relevant posts'] t = text.Transformer(MODEL_NAME, maxlen=256, class_names=categories) trn = t.preprocess_train(train['text'].to_numpy(), train['label'].to_numpy()) val = t.preprocess_test(test['text'].to_numpy(), test['label'].to_numpy()) model = t.get_classifier() model.compile(loss= focal_loss(alpha=0.25,from_logits=True), optimizer='adam', metrics=['accuracy']) #Run these two lines to find the best learning rate learner = ktrain.get_learner(model, train_data=trn, val_data=val, batch_size=16) learner.lr_find(show_plot=True, max_epochs=2)
After defining the model, we used ktrain to preprocess and tokenize the dataset as required by BERT:
(x_train, y_train), (x_test, y_test), preproc = text.texts_from_array(x_train=train_sentences.to_numpy(), y_train=y_train, x_test=val_sentences.to_numpy(), y_test=y_val, class_names=classes, preprocess_mode='bert', maxlen=256)
Then, we defined the evaluation metric that will be displayed by the model. For simplicity, we chose accuracy. Followed by compiling the model with the desired metric, ensuring that the correct loss function is used. Since our dataset represents a multi-class classification problem, we used categorical cross entropy as a loss function. If the problem was binary (e.g., toxic and non-toxic comments), we can use binary cross entropy as a loss function. For the optimizer, we used the default Adam optimizer, which is typically used in many neural network solutions. Next, we defined a ktrain learner to fine-tune and train the BERT language model.
METRICS = ['accuracy'] #Here we will just use accuracy model = text.text_classifier('bert', train_data=(x_train, y_train), preproc=preproc) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=METRICS) learner = ktrain.get_learner(model, train_data=(x_train, y_train), val_data = (x_test, y_test),batch_size=16)
Before proceeding with the training of the model, we defined a custom callback function to compute the Receiver Operator Characteristics-Area Under the Curve (ROC-AUC) score as a metric by the end of each epoch. ROC-AUC is a typical evaluation metric used with toxicity classification problems, thus, we used it to save the best trained model based on the highest ROC-AUC score.
from tensorflow.keras.callbacks import Callback class RocAucEvaluation(Callback): def __init__(self, validation_data=(), interval=1): super(Callback, self).__init__() self.interval = interval self.X_val, self.y_val = validation_data self.max_score = 0 self.not_better_count = 0 def on_epoch_end(self, epoch, logs={}): if epoch % self.interval == 0: y_pred = self.model.predict(self.X_val, verbose=1) score = roc_auc_score(self.y_val, y_pred) print("\n ROC-AUC - epoch: %d - score: %.6f \n" % (epoch+1, score)) if (score > self.max_score): print("*** New High Score (previous: %.6f) \n" % self.max_score) model.save_weights("best_weights.h5") self.max_score=score self.not_better_count = 0 else: self.not_better_count += 1 if self.not_better_count > 3: print("Epoch %05d: early stopping, high score = %.6f" % (epoch,self.max_score)) self.model.stop_training = True RocAuc = RocAucEvaluation(validation_data=(x_test,y_test), interval=1)
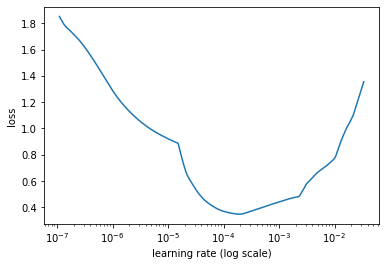
An important component of fine-tuning any neural network model is the learning rate. With ktrain, we can write one line of code to find the ideal learning rate based on our training set, as follows:
learner.lr_find(show_plot=True)
The step above is optional but allows us to identify the best learning rate that will yield the highest ROC-AUC score with minimal loss. After running this step, ktrain showed the following learning rate plot. Notice that the loss starts to drop at e-4, so choosing it as a learning rate fine-tuning parameter is a good option.
To train the model, we can simply write the following line of code:
learner.fit_onecycle(lr=1e-4,epochs=4,callbacks=[RocAuc],class_weight=weights)
This line of code means the following: take the pre-trained BERT learner and fine-tune it using the one cycle learning rate adjustment policy. The properties of fine-tuning this model include using the learning rate 10-4, using the ROC-AUC callback that was defined earlier, training the model over 4 epochs, and using the class weights while tuning the trained model.
Once the model gets trained, we can use a couple of lines of code by ktrain to evaluate the performance on the testing portion of the dataset as follows:
testing = preproc.preprocess_test(test_sentences.to_numpy(),y=y_tests) learner.validate(val_data=(testing),class_names=t.get_classes())
The learner.validate function call prints a classification report and a confusion matrix to summarize the performance, as shown here:
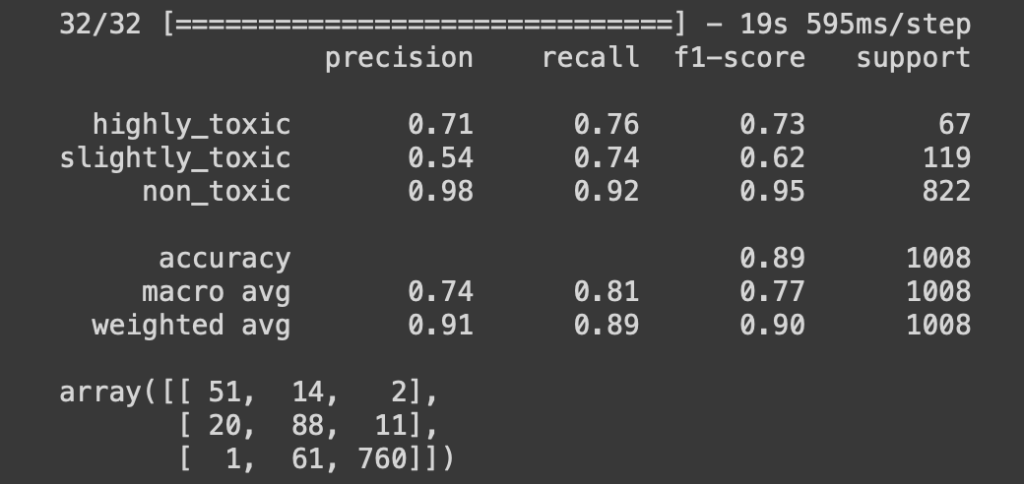
The results above show that our fine-tuned BERT model achieved an accuracy of 89%, which is not bad at all for detecting toxicity from comments in Reddit.
To showcase how the trained model can be used, we used ktrain to prepare a predictor object that can take any text and predicts its’ toxicity based on the fine-tuned BERT model.
predictor = ktrain.get_predictor(learner.model,preproc) examples = [ "If you don't stop immediately, I will kill you.", "Okay-- Take care sweetie.", "You fucking asshole! WTF is wrong with you?!" ] predictor.predict(examples)
In the code snippet above, we prepared three sentences that fall into the three categories of toxicity that our model can predict. If we apply common sense, we can guess which class each sentence belongs to. To verify that the model can predict the toxicity of each sentence, we called the predictor.predict function, which produced the following output:
![]()
Notice that our model was able to predict the class of each sentence correctly. Now, we have a fine-tuned BERT-based language model that can be used to detect toxicity from Reddit comments.
In conclusion, BERT provides a great starting point for fine-tuning language models. However, there are many ways to improve upon the model. For example, we can experiment with different hyperparameters, or we can train the model on more data to improve the accuracy or ROC-AUC scores.
Disclaimer: A portion of this blogpost was written with the assistance of open AI’s GPT3 Davinci’s engine.
The entire script is available on Google Colab
Happy coding!
References
[1] “What Is a Language Model?” https://www.deepset.ai/blog/what-is-a-language-model (accessed Nov. 19, 2022).
[2] D. Ash, “Language Models in AI,” unpack, Feb. 01, 2021. https://medium.com/unpackai/language-models-in-ai-70a318f43041 (accessed Nov. 19, 2022).
[3] K. Ganesan, “AI Document Classification: 5 Real-World Examples,” Opinosis Analytics, Aug. 21, 2020. https://www.opinosis-analytics.com/blog/document-classification/ (accessed Nov. 19, 2022).
[4] “What is BERT (Language Model) and How Does It Work?,” SearchEnterpriseAI. https://www.techtarget.com/searchenterpriseai/definition/BERT-language-model (accessed Nov. 19, 2022).
[5] H. Almerekhi, H. Kwak, and B. J. Jansen, “Investigating toxicity changes of cross-community redditors from 2 billion posts and comments,” PeerJ Comput. Sci., vol. 8, p. e1059, Aug. 2022, doi: 10.7717/peerj-cs.1059.
1 comment
Comments are closed.