In social media, likes and comments are key metrics for success.
If you can predict how many likes and comments a post will get, you can better manage your content strategy and create content that resonates with your audience.
There are a few ways to build a prediction model for the number of likes.
In this blog post, we examine and compare the prediction of likes and comments. Through following the framework for predicting audience engagement based on linguistic features [1]. We set the problem as a classification problem of two classes – high and low. We use Instagram data from a popular news media, but you can examine the same for your own account as well. Here we use a small dataset for the sake of faster examination of the prediction experiment.
Dataset
Using only the title of 7391 Instagram posts for one account, we analyze the text to extract language features for building prediction models. The input data contains three columns [‘comments’, ‘likes’, ‘title’ ].
Language Features
To construct the language features for the Instagram dataset, we take the title of all posts, and we remove all the special characters; then, we apply tokenization and stemming. Once we have cleaned the posts, we construct a TF-IDF matrix by setting the maximum number of features (i.e., words) at 1,000.
Prediction Experiment
We build a model that predicts the user engagement level of Instagram posts. We use binary classification models to predict the scale of engagement. The model predicts whether a given Instagram post’s title will have high or low audience engagement.
We consider the bottom 50% as posts with low engagement (label 1) and the top 50% as posts with high engagement (label 2).
For evaluating and comparing the prediction results, we use F1-score. We test a number of different classification algorithms, including Random Forest Classifier, Decision Tree Classifier, Support Vector Machines SVC, Logistic Regression, K Neighbors Classifier, and Gaussian Naive Bayes.
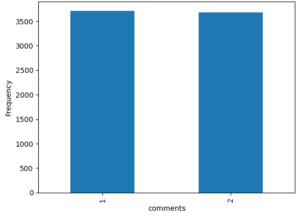
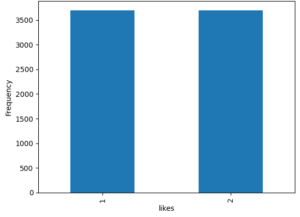
Figure 1: The bar chart showing the frequency of the posts in the classification classes low (1) and high (2) for Comments on the left side and likes on the right side.
Prediction Results
| Prediction Models | f1-score macro avg | |
| Comments | Likes | |
| Random Forest Classifier | 0.68 | 0.66 |
| Decision Tree Classifier | 0.66 | 0.64 |
| Support Vector Machines SVC | 0.73 | 0.68 |
| Logistic Regression | 0.73 | 0.67 |
| K Neighbors Classifier | 0.68 | 0.62 |
| Gaussian Naive Bayes | 0.70 | 0.66 |
Observations
We tested different basic models to compare the predictability power of both likes and comments. The best-performing model for predicting the number of comments (73%) and likes (68%) is the Support Vector Machines SVC model. The engagement metric that had the highest accuracy in predictability, using the TF-IDF language features and the tested models, was the number of comments. Whereas there is a 5% difference compared with the highest-performing model for predicting the likes. For all tested models, likes prediction performed less than comments prediction.
Based on the results of the prediction experiment, we can say that the number of likes is the engagement metric that is more difficult to predict. The number of comments can be predicted with higher accuracy.
The results can still be improved by fine-tuning the model parameters to get better results and increasing the size of the dataset. Also, by adding more metadata of the posts, such as the posting time, post frequency, hashtags, etc.
Using such an approach, you can predict how many likes and comments an Instagram post will get. With these prediction insights, you can better manage your content strategy and create content that will better resonate with your audience.
[1] Aldous, K, An, J, and Jansen, B. J. (2019) Predicting Audience Engagement Across Social Media Platforms in the News Domain. 11th International Conference on Social Informatics (SocInfo2019). Doha, Qatar. 18-21 November, 173-187.